Maigo 2006.1.14
我们知道trie树(也叫字母树)这种数据结构。它是词典的一种存储方式。词典中的每一个单词在trie树中表现为一条从根结点出发的路径,路径中边上的字母连起来就形成对应的单词。图1就是一棵trie树,其中含有a,abc,bac,bbc,ca五个单词。
利用trie树可以对词典中的单词进行一些适合用树这种数据结构进行的操作,如求两个单词的公共前缀长度(在树中表现为求两个单词对应结点的最近公共祖先)。其实,如果把trie树加以改造,多连一些边,形成的trie图在解决多模式串匹配问题上会发挥奇效。
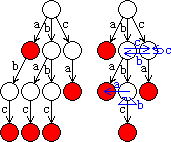
左:图1,一棵含有五个单词的trie树。红色表示单词终止的位置。
右:图2,由图1的trie树改造成的trie图。红色表示危险结点,白色表示真安全结点,蓝色表示新加的边。为简单起见,危险结点以下的结点及与之关联的边没有画出。
一、Trie图的构建
我们通过一个例题来探究trie图的构建方法。
【例1】不良单词探测器
【题目描述】给出一个词典,其中的单词为不良单词。单词均为小写字母。再给出一段文本,文本的每一行也由小写字母构成。判断文本中是否含有任何不良单词。例如,若rob是不良单词,那么文本problem含有不良单词。
【输入】第一行为一个整数n,表示不良单词的个数。接下来n行是词典。下面一行为一个整数m,表示文本的行数。接下来m行是文本。
【输出】如果文本包含不良单词,输出一行“Yes”,否则输出一行“No”。
【样例输入】
1
rob
1
internetproblemsolvingcontest【样例输出】
Yes
【备注】因本题只是用来讨论trie图的构建方法,故未给出数据范围。
【分析】判断文本是否包含不良单词可以一行一行地判断。而判断长为L的一行文本s是否含有不良单词可以这样进行:让i从1变化到L,依次判断s的前i个字符构成的字符串是否以不良单词结尾。
然而,我们希望在判断s的前k个字符时,能够利用前k-1个字符的结果,即这两个状态间可以方便地进行转移。注意到trie树中的边正如一个个“方向标”,因此我们有了一个美好的设想:从根结点出发,沿着标有s[1]的边走一步,再沿标有s[2]的边走一步,一直这样走下去!
现在有了一个问题:如果从当前走到的结点出发,没有需要走的边,该怎么办?只要“创造”一条这样的边即可。那么这条边应该指向哪个结点呢?如果同样“创造”一个结点,那是毫无意义的。解决这个问题,要从我们“沿边走”的动机谈起。
我们之所以“沿边走”,是因为我们把结点看成了状态,把边看成了状态间转移的途径。要确定新加的边应连到哪个结点,就需要找我们想走到但去不存在的那个结点与已有的哪个结点是等价的。那么“等价”的标准是什么呢?我们先来解决另一个问题:
定义trie树中从根结点到某个结点的路径上的边上的字符连起来形成的字符串为这个结点的路径字符串。如果一个结点的路径字符串以不良单词结尾,那么称这个结点为危险结点,否则称之为安全结点。那么如何判断某个结点是否危险呢?
显然根结点是安全结点。对于一个非根结点,它是危险结点的充要条件是:它的路径字符串本身就是一个不良单词,或者它的路径字符串的后缀(一个字符串去掉第一个字符后剩下的部分叫做它的后缀)对应的结点(一个字符串对应的结点是指在trie图中从根出发,依次沿该字符串的每个字符走一步所达到的结点)是危险结点。如果称一个结点的路径字符串的后缀对应的结点为它的后缀结点,那么如何求任一结点的后缀结点呢?
根结点的后缀结点是它本身。处于trie树第二层的结点的后缀结点也是根结点。对于再往下的某个结点,设它的路径字符串的最后一个字符为c,那么这个结点的后缀为从它在trie树中父结点的后缀结点出发,沿标有c的边走一步后到达的结点。(下文中称从x结点出发,沿标有字符c的边走一步到达的结点为x的c孩子)
那么,如果它的父结点的后缀结点w没有c孩子怎么办呢?到此,我们看到两个问题已经合而为一了。我们假设w有这样一个c孩子(记作x),并且从x出发又繁衍出无数的子子孙孙。我们来判断以x为根的子树中的结点的危险性。显然x本身的路径字符串不是不良单词,且它的子孙的路径字符串也不是不良单词。因此以x为根的子树中任一结点y的危险性与y的后缀结点的危险性相同(回忆一下一个非根结点是危险结点的充要条件)。这也就是说,以x为根的子树与以x的后缀结点为根的子树是一模一样的。因此,我们把需要新建的从w指向x的边直接指向x的后缀结点,即w结点的后缀结点的c孩子即可。简言之,由于x本身的路径字符串既不是不良单词,又不是某个不良单词开头的一部分,所以它的首字母便没有用了!在这种情况下,x结点就等价于它的后缀结点。
由此我们可以把trie树改造成一个有向图:
按层次遍历trie树,求出每个结点的危险性和后缀结点,并补齐由它出发的边。危险性与后缀结点的求法在【分析】部分第6、7自然段已有说明;若当前结点为根结点,则补充的边应指向本身,否则若x没有c孩子,则新建一条这样的边,指向x的后缀结点的c孩子。
处理某个结点的过程中需要用到深度比它小的结点的后缀结点及各个孩子。由于我们按层次遍历trie树,这些信息都已求得。
这样由trie树改造成的有向图就叫做trie图。图2就是由图1的trie树改造成的trie图。我们美好的设想终于变成了现实。由根结点出发,按照文本中的字符一步步走下去。若走到一个危险结点,则发现了一个不良单词;若一直没走到危险结点,则文本不含不良单词。
本题的算法还可稍加优化。把安全结点分为两类:如果在trie树中由根结点到某个安全结点的路径上没有危险结点,那么称这个安全结点为真安全结点,否则称之为假安全结点。由于新建的边的终点的深度不会大于起点的深度,因此要到达一个假安全结点,必须经过一个危险结点。而在本题中,一旦到达一个危险结点,程序就会停止,因此假安全结点是没有用的,也就是说,在本题trie图的构建过程中,若发现一个危险结点,那么它及它的子孙的属性都不必计算了。
如果用L1、L2分别表示不良单词和文本的总长度,用a表示字符集中字符的个数,那么trie图的时间复杂度为O(L1a+L2),空间复杂度为O(L1a)。
二、Trie图的活用
在上面的例题中,我们在trie图中记录了每个结点的危险性、后缀结点,并通过按层次遍历得到了图中结点的一个BFS序。其实,trie图中可以记录的信息不止这些;得到的BFS序也并不是毫无用处。
【例2】字谜(题目来源:SPOJ WPUZZLES)
【题目描述】给定一个L行C列的、由大写字母构成的矩阵,以及W个单词。每个单词可在矩阵中的任何位置朝着任何方向出现,且仅出现一次。编程找出每个单词的首字母在矩阵中的位置,以及单词的朝向。
【输入(标准输入)】第一行为一个整数T,表示数据的组数。下面有T组数据。每组数据中:
第1行为三个不超过1000的整数L、C、W。
下面L行,每行C个大写字母,表示矩阵。
下面W行,每行一个单词。
【输出(标准输出)】对每组数据,输出W行,每行为两个整数和一个字母,之间用一个空格隔开。第i行的两个整数表示第i个单词首字母的行号和列号(从上至下依次为第0至L-1行,从左往右依次为第0至C-1列);字母表示单词的朝向,对应关系如下:
字母 | A | B | C | D | E | F | G | H |
朝向 | 上 | 右上 | 右 | 右下 | 下 | 左下 | 左 | 左上 |
相邻两组数据的输出之间用一个空行隔开。
【样例输入】
1
4 5 4
MAIGO
QKRPT
AREMO
WERTY
AKI
MAIGO
ARM
ARMY【样例输出】
2 0 B
0 0 C
0 1 D
0 1 D【分析】本题中多模式匹配的模型是显而易见的。由于要求的是每个单词首字母的位置,我们在建trie图时,把每个单词都反过来,如单词MAIGO变成OGIAM。对每个方向的每一串字母进行一次多模式匹配,就可以找到所有的单词了。
在本题的trie图中,仅仅记录每个结点的危险性是不够的,还要记下每个结点的危险性是由哪个单词引起的。我们定义危险结点x的危险源:若x的路径字符串本身就是不良单词,那么它的危险源就是该单词;否则x的危险源就是它后缀结点的危险源。每个结点的危险源可以在后缀结点的过程中求出。
那么,是不是每走到一个危险结点,便记下危险源的位置及朝向就可以了呢?不是的。比如在样例中,当我们沿着左上方向扫描(3,4)-(0,1)这个字符串(YMRA),到达字母A时,由于该结点的危险源是YMRA,我们便记下了ARMY的位置和朝向。但同时我们就把单词ARM漏掉了。正确的做法是,当遇到一个危险结点时,记下它的危险源的位置和朝向,同时继续检查危险源对应结点的后缀结点,直到到达一个安全结点为止。
【注】本题的字符集虽然只有26个字母,但trie图中结点的数目可能达到1,000,000,内存复杂度太高。这个问题留待第三部分解决。
通过《字谜》一题我们学会了如何在trie图中记下更多的信息。下面简述一下对BFS序的应用。
在做多模式匹配时,有时仅仅找到不良单词是不够的,还要统计出每个单词出现的次数。进行这项工作时,我们并不需要判断每个结点的危险性,而只需累加经过每个结点的次数。但这时有单词对应的结点的访问次数并不就是这个单词出现的次数,比如在图2中,单词a出现时光标完全可能在结点ba上。因此我们自底向上地把每个结点的访问次数加到它的后缀结点上。这样处理之后,有单词对应的结点的访问次数就代表这个单词出现的次数了。
上面介绍了trie图的一些初步活用。但如果仅仅用trie图来做多模式匹配,那就太大材小用了。下面再通过几个例题来说明trie图的更灵活的应用。
从例1可以看到,危险结点在图中往往是一些障碍,在许多用到trie图的问题中,有用的结点只有真安全结点。我们把trie图中的真安全结点以及它们之间的边构成的子图叫做安全图。
【例3】病毒(题目来源:POI #7)
【题目描述】已知某些特定的01串是病毒的特征代码。如果一个01串不含有任何病毒特征代码,则称它为一段安全代码。给定病毒特征库,判断是否存在无限长的安全代码。
【输入(文件wir.in)】第一行为一个整数n,表示病毒特征代码的条数。下面n行,每行一段病毒特征代码。所有代码长度之和不超过30000。
【输出(文件wir.out)】若存在无限长的安全代码,输出一行“TAK”,否则输出一行“NIE”。
【样例输入】
3
01
11
00000【样例输出】
NIE
【分析】“无限长”的安全代码是什么意思呢?就是说从根结点出发,在安全图中可以走无限步。“无限步”又是什么意思呢?就是说安全图中有环。因此我们建立一个trie图并对其安全图进行拓扑排序,若成功,则安全图无环,输出“NIE”,否则输出“TAK”。
【例4】Censored!(题目来源:Ural 1158)
【题目描述】已知一个由n(1<=n<=50)个字符组成的字符集及p(0<=p<=10)个不良单词(长度均不超过10),求长度为m(1<=m<=50)且不含不良单词的字符串的数目。
【输入(标准输入)】第一行为三个整数n,m,p。第二行为n个字符,表示字符集。下面p行,每行一个不良单词。
【输出(标准输出)】一个整数,表示长度为m且不含不良单词的字符串的数目。
【样例输入】
3 3 3
QWE
QQ
WEE
Q【样例输出】
7
【分析】求长度为m且不含不良单词的字符串的数目,就是求在安全图中从根结点出发走m步有多少种走法。用count[step,x]表示从根结点出发走step步到结点x的走法数,则容易写出下面的伪代码:
fillchar(count,sizeof(count),0);
count[0,根]:=1;
for step:=1 to m do
for 安全图中每条边(i,j) do
inc(count[step,j],count[step-1,i]);
ans:=0;
for 安全图中每个结点x do
inc(ans,count[m,x]);显然,本题还需要用高精度。
我们看到,trie图的安全图上还是大有文章可做的。Trie图(或其安全图)作为一个有向图,它具有一般有向图具有的性质,因此在它上面可以进行拓扑排序。同样,它的有向性也可以成为动态规划划分阶段的依据。
三、Trie图的改进
Trie图的空间复杂度是比较高的,当trie图中结点个数较多或字符集较大时,内存根本无法承受。下面探讨这个问题的解决方法。
【例5】不良单词过滤器(题目来源:Ural 1269)
【题目描述】给出一个词典,其中的单词为不良单词。再给出一段文本,文本的每一行可能包含除chr(0),chr(10),chr(13)外的任何字符。若文本中有不良单词,找出文本中不良单词第一次出现的位置,若没有,输出一行“Passed”。
【输入(标准输入)】第一行为一个整数n(1<=n<=10000),表示不良单词的个数。接下来n行是词典。词典的大小不超过100KB,每个不良单词的长度不超过10000。下面一行为一个整数m,表示文本的行数。接下来m行是文本。文本的大小不超过900KB。
【输出(标准输出)】若文本中有不良单词,输出一行两个整数,表示不良单词第一次出现的行和列,用一个空格隔开。若文本中无不良单词,输入一行“Passed”。
【样例输入】
2
rob
Problem
1
Internet Problem Solving Contest【样例输出】
1 10
【注意】样例中“第一次出现”的不良单词是Problem而不是rob,虽然rob比Problem先结束。
【时间限制】1s。
【内存限制】5000KB。
【分析】乍一看,这道题与例1不是一模一样的吗?其实不然。与例1相比,这道题的字符集大得多,如果直接建trie图,从每个结点出发要建253条边,而结点数最多为100000,严重超内存。试想一下,如果要做一个汉字的多模式匹配系统,岂不是要从每个结点出发建几千几万条边呢?所以,为解决此问题,trie图的改进势在必行。
我们看到,在本题中,算法的瓶颈在于从每个结点出发的边数。那么我们自然会想到:一定要存储所有的边吗?答案是否定的。Trie树中的边自然是要存储的(用左孩子右兄弟表示法),但新建的边则不必存储。如果不存储新建的边,那么如何实现状态间的转移呢?我们用一个函数child(x,c)来获得结点x的c孩子。函数内部的程序其实完全是按照加边的原则编写的:如果x本来就有c孩子,那么就返回这个孩子;如果x没有c孩子,根据加边的原则,函数应该返回x的后缀结点的c孩子,也就是令x为它的后缀结点,重新执行函数。如果x变成了根结点仍然没有c孩子,同样根据加边的原则,函数的返回值就应该是根结点本身。
经过这样的处理,算法的空间复杂度由O(L1a)降到了O(L1),对于本题来说是足够低的了。但是,由于child函数的执行时间的不确定性,我们对算法的时间复杂度产生了疑问。其实,算法的时间复杂度为O(L1+L2),数量级并没有受到影响,只是增加了一点常数系数。为什么呢?显然,在调用child(x,c)的时候,只有当x没有c孩子,需要重复执行child函数时运行时间才会增加。我们分别讨论增加的这点时间对建图过程和文本检查过程所需时间的影响:
- 建图过程:由于我们并不存储一个结点的所有孩子指针,所以建图的过程其实就是求每个结点的后缀结点的过程。若b是trie树中a结点的一个孩子,那么b的后缀结点的深度至多比a的后缀结点大1。如果把trie树中某条路径上的结点的后缀结点的深度排成一个数列,那么相邻两项中,后一项减一项的差一定小于等于1。当后一项减前一项的差小于1时,child函数就会被重复执行。但是,child函数回溯的次数不会超过trie树的深度,所以建图过程的时间复杂度为O(L1)。
- 文本检查过程:把这个过程看成是一个光标在安全图中漫游的过程。因为光标如果往下走,它只能走1步,所以若把光标经过的位置的深度也排成一个数列,这个数列与上一段提到的数列具有相同的性质:增长是缓慢的。同理,文本检查过程的时间复杂度为O(L2)。
综上所述,改进后的trie图的时间复杂度为O(L1+L2)。无论从时间复杂度上看还是从空间复杂度上看,改进后的算法都明显优于改进前。第二部分中的《字谜》一题到此也得到了圆满解决。其实,改进后的算法已经就是用于多模式串匹配的改进KMP算法了。
对于什么样的题目需要用改进的trie图,在此作一下总结:
- 纯粹的多模式匹配问题:当题目中的字符集大小有限且较小时,不必用改进的trie图,因为内存够用,若进行改进,增加的常数系数可能反而大于字符集的大小a。如果字符集较大甚至无限(汉字的多模式匹配系统的字符集几乎可以认为是无限的),就必须使用改进的trie图。
- 用到图中每一条边的题目(如第二部分中提到的拓扑排序、动态规划等):一般用未改进的trie图。在内存十分紧张的情况下,可以采用改进的trie图,用时间换空间,但这样做时间复杂度仍为O(L1a+L2),且常数系数较未改进时大。
附:
《病毒》一题的程序:

program wir;
const
maxl=30001;
var
child:array[1..maxl,0..1]of word;
danger:array[1..maxl]of boolean;
suffix,indeg,q:array[1..maxl]of word;
nodes,n,p,d,i,f,r:word;
c:char;
procedure build_trie;
begin
nodes:=1;
readln(n);
for i:=1 to n do begin
p:=1;
repeat
read(c);d:=ord(c)-48;
if child[p,d]=0 then begin
inc(nodes);child[p,d]:=nodes;
end;
p:=child[p,d];
if danger[p] then break;
until seekeoln;
danger[p]:=true;readln;
end;
end;
procedure build_graph;
begin
f:=0;r:=0;nodes:=1;
for d:=0 to 1 do
if child[1,d]=0 then begin
child[1,d]:=1;inc(indeg[1]);
end
else begin
inc(r);q[r]:=child[1,d];suffix[child[1,d]]:=1;inc(indeg[child[1,d]]);
end;
repeat
inc(f);
danger[q[f]]:=danger[q[f]] or danger[suffix[q[f]]];
if not danger[q[f]] then begin
inc(nodes);
for d:=0 to 1 do begin
if child[q[f],d]=0 then
child[q[f],d]:=child[suffix[q[f]],d]
else begin
inc(r);q[r]:=child[q[f],d];suffix[q[r]]:=child[suffix[q[f]],d];
end;
inc(indeg[child[q[f],d]]);
end;
end;
until f=r;
end;
procedure toposort;
begin
if indeg[1]>0 then begin writeln('TAK');exit;end;
f:=0;r:=1;q[r]:=1;
repeat
inc(f);
for d:=0 to 1 do begin
p:=child[q[f],d];
if danger[p] then continue;
dec(indeg[p]);
if indeg[p]=0 then begin
inc(r);q[r]:=p;
end;
end;
until f=r;
if r<nodes then writeln('TAK') else writeln('NIE');
end;
begin
assign(input,'wir.in');reset(input);
assign(output,'wir.out');rewrite(output);
build_trie;
build_graph;
toposort;
close(input);close(output);
end.
《字谜》一题的程序可以在http://purety.jp/akisame/oi/SPOJ.rar下载。
《Censored!》和《不良单词过滤器》的程序可以在http://purety.jp/akisame/oi/URAL.rar下载。
作者资料
王赟(Maigo):Facebook 语音组研究科学家。2006至2010年就读于清华大学电子工程系,并以第一的成绩进入美国卡内基梅隆大学(CMU);2010至2018年于卡内基梅隆大学计算机学院语言技术研究所攻读博士学位,主攻方向为语音识别、音频事件检测。曾于2004年、2005年参加全国信息学奥林匹克竞赛(NOI),并分别获得铜牌、银牌;此后曾辅导多名同学参加互联网公司的面试。于业余时间自学了日语、韩语、西班牙语、法语、越南语5门外语及中古汉语,并制作了安卓应用“汉字古今中外读音查询”。日常活跃于知乎,擅长回答数学、计算机、语言类问题,并在知乎专栏发表多篇优质文章,关注者超过14万。
@王赟 Maigo是卡内基梅隆大学(CMU)语言技术研究所(LTI)的博士生。他2010年以硕士的身份加入研究所,12年继续在所内攻读博士,研究方向是语音识别。在此之前,他在清华大学电子工程系完成了本科,也入选过信息学竞赛国家集训队。业余时间,他是一名骑行爱好者,也掌握了六门外语(英日韩西法越)。此外,他在知乎上贡献了两千多条高质量回答,在社区中有很大的知名度。我们主要聊了:
– 语音识别领域包括哪些内容?目前的技术难点和落地前景如何?
– 掌握六门外语是怎样的经历?有哪些经验?
– 硕博申请:CMU硕士原地申请PhD有哪些优势?
– 作为回答了2700多个问题的知乎大V,怎么看待知乎的变化?
王 = 王赟
#1. 语音识别:第一大街还是第六十一大街?
简单介绍一下你的个人经历和求学经历。
王:我2006-2010年在清华电子工程系就读,之后申请到了卡内基梅隆大学(CMU)。先是读了两年硕士,是计算机系下面的语言技术研究所 (Language Technology Institute),然后原地继续读博士。到现在博士一共读了五年,马上要开题了,大概还有一年毕业。
我做的研究都是和语音相关的。最早开始也是因为兴趣的驱动,我高一时在报纸上看到日本雅马哈公司发布了一个软件,叫Vocaloid(现在知名度很高,在二次元圈子中用来制作音乐)。我很好奇它的原理,就埋下了研究语音识别的种子。
语音识别是什么?它的研究内容包括哪些?
王:语音识别是把一段声音识别出来变成文字,它还有一些周围的应用,比如手机上的 Siri 助手能识别用户的语音指令,并根据指令去做别的事情。
现在基本的语音识别功能已成熟,在较好的条件下(比如安静的办公室,说话的语速、口音正常,没有很多停顿),识别准确率可达90%以上。
但在不那么好的条件下,例如背景带噪声或是说话有口音,识别率会有显著下降,也是现在研究的热点方向。
我注意现在到国内对于方言的研究还是挺多的,讯飞和搜狗都推出了语音输入法,其中就有支持方言。
有没有遇到过有意思的语音识别功能?
王:有些功能是我看到后会会心一笑的,因为我知道它里面发生了什么。比如有一次导航我说了一个美国地址(门牌号在前,街名在后),第一大街660号(Six sixty, First Avenue)。
看到它一开始识别为第六十一大街6号(Six, Sixty-first Avenue)。反应了半秒钟发现匹兹堡市没有六十一大街,就明白过来了,把这个结果纠正了。
你自己做的项目有哪些?
王:我做的是和语音有关的周围项目。现在的博士项目做的是音频事件的检测,不是针对说话内容,而是声音里面的其他事件,比如敲门或是警车开过。之前还做过关键词检索,用户会想在录音中找一个特定的词。
比如用户想搜索”警车“,关键词搜索会告诉你,这段谈话的16分14秒有警车这个词出现;而我现在做的音频事件可以告诉你,在16分14秒有警车的声音。
在你提到的研究当中,碰到的难点是什么?
王:现在做语音识别一般用深度学习,需要很大的神经网络和大量数据,所以开始训练模型后要两三天才有结果。另外在训练网络的时候要调整超参数,并没有万能的通法。
语音识别领域的一个特定问题是研究者不一定懂这门语言,当神经网络的结果不理想,有时候不知道该怎么调整。
但有时还真得硬着头皮研究数据,比如不懂这门语言,但是从数据搜集者那里会收到一个字典,可以把文本串转化为音素串,比如国际音标,对着看,偶尔也能看出问题。
语音识别在商业方面的落地应用会是怎么样?
王:声音转文字本身开始投入使用了,随着深度学习技术的发展也会随时跟进。周边项目,比如我说的音频事件检测,离应用还有一段距离,目前的问题在于数据量不够。
现在谷歌等大公司在积极收集数据,并且进行人工标注。但要等数据更多、网络更强,才能看到实用的那天。这个过程我认为至少还要五年。
#2. 申请经验:带奖CMU硕士、原地申博士
能不能分享一下申请CMU硕博时候的经验?
王:09年底10年初申请的时候,我一共申请了美国的11所大学(低于平均值,因为一般人的申请数量在15-20所)。这11个里面,2个给了PhD offer,2个是master(包括CMU)。
给 PhD offer 的一个是普渡大学,但我想进的那个实验室正巧解散了,做语音识别的两个教授去了别的地方,另一个是 UCSD,来的比较晚,所以都没有考虑。
最终在斯坦福和 CMU 两所给了硕士的学校中选择。一开始也没料到会只给我硕士,但我当时得知 CMU 的硕士项目和博士非常像,也是要一边上课一边做研究。而且它也像博士一样有奖学金。我就选了 CMU 这个项目。
CMU 硕士申请博士是一个怎样的过程呢?
王:CMU 硕士到博士还是要经历一个申请的过程。原地申请有一个很大的优势是系里的教授都认识你了,如果硕士两年表现积极、给教授留下好印象,他们就会很愿意给你写推荐信。
#3. 六门外语,从唱主题曲开始
你出于兴趣学了六门外语,这是怎样一种经历?
王:感觉很奇妙,我学语言是出于兴趣,和专业研究内容关系不大。小时候看大风车的动画片主题曲是日语,觉得日语的文字很好看,歌也好听,就有了兴趣。到小学的时候,我有了一本日语书,把五十音图背了下来,意思也不懂地唱了几年歌。从初二才正式开始学日语了。
高中的时开始学韩语,当时韩剧《我的野蛮女友》的主题曲到处传唱,我对着字母表研究发音,把歌词背了下来,这样一来就想学韩语了。大学的时候经常去学校的日语角,也创办了中韩交流协会,召集中韩学生在一起学习玩乐。
从高中一直到大三,我满足于中英日韩这几门语言,并不想做 polyglot(多语言者)。但大三的暑假我到美国洛杉矶的南加州大学交换。那里靠近墨西哥,有很多说西班牙语的人,我也就开始学西语,从这个时候算是走上了 polyglot 道路。
回去之后在中韩交流协会中有一个法国的同学,我就开始学法语。我学的最后一门外语是越南语。因为中日韩越南朝鲜是统称为汉字文化圈,我就想只差越南语,干脆就学了。
你在学语言的过程有什么经验可以分享?
王:我学语言的方法可能跟一般人不太一样。一方面是我已经学了很多种语言了,如果要接触一门新语言,我会拿它去和我学过的进行类比,寻找相似之处,有这种迁移就会学的很快。
另一方面,我会把人类的语言也当成一种编程语言去看,注重语法规则。拿到一门语言先学它的发音和文字,我会注重发音和字母之间的对应关系,试图去总结出一些规则来。
基础关过了之后,以语法为线索来学一门语言,像词汇、对话这些一开始够用就行。等语法的框架搭起来之后,添枝加叶就会很快。
#4. 知乎:最多有几个汉字能两两组词?
你在知乎上回答过2700+个问题,印象最深的是哪一个?
王:这些问题都很有意思,比如在语言方面上,会有专业和通俗之分。有一个通俗的好玩的问题就是,最多能找到多少字,使它们两两之间都能组成词?
我举个例子,比如“春秋风雨”这几个字,两两之间全都能组成词。比如再往里面加一个“大”,大风大雨可以,但大春大秋就不行。
那能往里面加什么呢?这个问题如果让人去想的话还是挺碰运气的,取决于你的思维是不是开放,比较适合的方法是编程去做,你有一个足够大的词库,就会有一个算法从中找到最多的字,让它们两两之间组成词。当时这个回答得到了上千的赞。
知乎在最近几年用户数量在不断增加,你有没有感觉到什么变化?
王:我相当于见证了知乎的大部分历史。11年的时候知乎创建,我从13年开始大规模使用。之前,在知乎的”黄金时期“,它还是一个比较小的圈子内进行高质量的交流。我从白银时代开始,相当于第二批用户,会有具备专业知识和真知灼见的用户进行互动。
再往后,知乎随着规模慢慢增大变成了一个普通的论坛 ,用户的质量有下降,话题变水。好在我在白银时代结识的这些朋友也都还在,虽然精华的密度下降了,但还是能刷到一些东西,所以也是我愿意留在那的一个原因。
另一个方面是建立了激励之后,你就会想去维护它,不断地发展壮大,而不会轻易地换一个地方。
你平时信息的来源是什么?
王:主要的信息来源是知乎,有深度的讨论。我在深度学习、语音识别领域也关注了很多,会了解很多学术界的前沿消息。新闻也是以知乎为主,现在的套路就是每出一个新闻,就会有一个”如何评价“的问题。
还有一个来源是 YouTube。我关注了一些比较有意思的频道,比如有一个叫 Numberphile,会讲一些数学上的好玩的东西,还有一些学语言的频道,比如 talk to me in Korean。这些频道会发一些5-10分钟的短视频,讲一个小话题。
嘉宾联系方式:
个人主页:http://www.cs.cmu.edu/~yunwang/
王赟(Maigo),卡内基梅隆大学计算机学院语言技术研究所在读PhD。曾在2005年入选全国信息学竞赛国家集训队,网上流传着他写的各大题库的程序和解题报告。曾获得保送资格,但依然以山东烟台市状元的成绩考上了清华大学电子系,又以全系第一的成绩进入卡内基梅隆大学。
近期,博士毕业生王赟在网络上写了一篇留学生涯的贴子,道出他在人工智能相关领域求学的点滴、感悟和精彩生活,引起网友热议。从2010 年8 月到2018 年10 月,王赟把最好的青春年华献给了博士学习。“其中前两年是硕士,但由于硕士生活跟博士并没有太大区别,都要做研究,所以说八年博士也并不过分吧。”在就读期间,他换了2个研究项目,做了3个项目,拿到博士学位时间略微超出平均值。
也正是走过这样一段弯路,他在2014年搭上了深度学习的快车,也赶上2017年弱标注事件大数据公布的风口,做出了如今让他满意的“弱标注下的音频事件检测”研究成果。“我并不觉得我前四年是荒废了的。整整八年的学习,让我对语音识别、深度学习等各个领域的理论基础有了扎实的掌握。”
他并没有散发出苦的气息,而是整天乐呵呵的地把留学生活过得多姿多彩——他走进社团、周游城市、全世界旅游,结识了许多非常有趣的朋友。
王赟
王赟在网上发布的留学生涯的帖子写得非常有趣,有些意外这是一个理科工学生的手笔。与他交谈也非常愉快和放松。
1
他的眼中只有语音
王赟高中就读于山东龙口一中,昔日的校友在网上直呼高中时代他就是一个学霸。
“像数学物理化学这方面从中学时代就已经有比较浓厚的兴趣了,高中参加过信息学竞赛,编程算法这些学得比较早。”在他看来,当时这些还算挺新的东西。也就是在高中的时期,他对语音方面就萌发了兴趣,他记得,读高一时了解到日本出的一款用电脑合成唱歌的软件,“就觉得这个东西挺好玩,然后就想将来我也可以做一款类似的东西,然后从那个时候开始有了兴趣。”在这背后还有他喜爱唱歌这一推动因,“我比较喜欢唱歌,学了好多首歌,这个东西正好可以合成歌曲。”为此,后来上了大学,他“自主研发”了一套系统。
在清华,他完成了这个深藏已久的心愿。2006年,王赟考入清华大学电子工程系,大一的时候,他就着手完成这个小心愿,“写了一个简陋的合成系统出来,(系统)还凑合,很明显是合成音,不过能听出是唱歌声。(笑)”牛刀小试后,他感到一些成就感,当时想如果以后有这种机会的话,希望往这个方向发展。
语音合成只是他纵身跃入兴趣领域的入口,是语音识别还是语音合成都无所谓,“只要跟语音信号有关系的东西,我都比较有兴趣。”电子工程系中的一门课信号处理,王赟学得比较扎实,“因为语音本身就是一个信号,所以这个可以算是看家本领。”他说,语音本身就是一个信号,它是一个波形样态,你怎么对它处理来提取里面有用的信息,经过电子系的训练之后,这方面的功力会比较扎实一些。
在本科阶段,王赟眼中关注的都是语音,也发表了第一篇署名为第一作者的论文。那时候人工智能还不是如现在这般火,他也阴差阳错成了人工智能领域最早的一批先行者。
2
8年博士生涯
本科毕业以后,王赟在发展语音兴趣路上越走越远,走出了国门去留学。他申请到两所大学的研究生。一般而言,攻读硕士学位比较难拿到奖学金,而其中一所大学的项目很特殊,给了奖学金,于是他选择了这所大学。
王赟前2年读硕士,做的事跟博士几乎没有两样,一半时间上课一半时间做研究。从硕士到博士的中间需要再申请一次,但是因为他已经在那,教授们都见过,评价的依据就比较丰富,“就这样自然而然申请上博士。”
从入学到2012 年春天,王赟跟随老师研究说话人识别(分为说话人辨认和说话人确认)。他说,做说话人识别,一般不管说的是什么内容,哪怕你听不懂,也能听出来是谁在说话。在这将近两年的时间里,王赟用Matlab 语言亲自实现了十几种语音特征的提取。
“那时候博士申请结果已经出来了,所以说不会有特别紧张,但从技术上来看是个遗憾,因为没有在市场上火起来。”后来,王赟转到一位高高胖胖的德国教授名下攻读博士,名字发音和英语的花朵有些相似,于是在中文的语境中,王赟称导师为“花哥”。
3
博士三年仍未发论文
投身花哥门下,王赟做的第一个项目是Babel,其任务是在多种小语种语音里检索关键词,这个项目是由全世界许多大学和公司共同参与,大学或公司合作组队伍,而队伍之间互相PK,最后优胜劣汰,留下好的项目。
这是一个规模很大的系统,前期要完成一个从无到有的过程,有了这个基础之后,才能做研究。王赟形容前期搭建系统“与其说是像科研,不如说是像工作”。2014年,王赟才从工程性工作中脱身出来,开始做有价值的科研工作,比如如何更准确地给检索到的每个关键词的可靠性打分。然而好景不长。2014年6月,正当王赟在韩国游玩的时候,实验室的同学发来噩耗:王赟所在的队伍被淘汰。这犹如晴天霹雳。那个时候他在想下面做什么好。
王赟(左2)和朋友一起游玩。
“我一下子不知道将来的路就是怎么走。”而此时是王赟留学的第四年,到此时为止,他只发出了一篇署名为第一作者的论文,另外一篇论文屡投屡不中,最后只能将其尘封。他当时就知道这个博士可能会是一场马拉松,经过前面一两年的热身很正常,但到了第三年还没科研产出,这对于博士来说,是一件很惊悚的事情。“知乎上有一个这样的问题:博士第三年还没有发论文是一种怎样的体验?我想我是最适合回答的,但终究没有勇气回答。”那时起,他做好了读博六年七年八年的准备。
第四年的这篇论文让他的焦虑得以缓解。“感觉就是从0到1的质变。”2014年下半年,他经历了近乎搏命的半年。在这半年他阅读了近百篇论文,还在网上学习了深度学习三巨头之一Geoffrey Hinton的课程,系统地学了其中的技术。这得益于2013年、2014年在做项目过程中学习到的最前沿的东西。在2014年9月新加坡举行的Interspeech 会议上,他嗅到了深度学习正在崛起的信号。“深度学习这个工具我已经掌握了,我知道终究有爆发的一天。”
4
抢占学术荣誉高地
博士论文的最终选题王赟确定为事件检测。他打比方说,事件有低层和高层之分,底层的事件,比如猫叫、狗叫、开关门,比较高层的事件,比如球赛、婚礼、聚会等。当时选择这个方向,王赟并没有感觉到它的魅力在哪,现在看来,当时正好是万事俱备,只欠东风,也就是说技术的发展差不多到了能够做这些事情(事件检测)的时候了。
在2016 年3 月的ICASSP 会议上,芬兰Tempere 理工大学的研究组与王赟同时发表了用深度学习做底层事件检测的论文。在这场关乎学术荣誉的阵地战中,王赟走在了前列。当时,王赟关注到芬兰那边有个实验室小组也在做类似的课题,他想着的不能落后于人,于是有了这场竞赛,最后他们平分秋色,“我们两个是同时发出来的,所以后来我们两个都被引用,感觉算是在这个领域内,我也是并列第一个做研究的,算是第一波里面的先行者之一。”
“就从这个时候开始,我觉得算是我这个博士研究走上正道了,开始以相对固定的节奏发论文了。”后来,他明显感觉做研究的数据不足,总共就10几个小时的数据,在深度学习面前这点数据无疑是杯水车薪,“没有数据,就是巧妇难为无米之炊啊!”就在他为此苦思不得之际,他有如神助——每条长度为10 秒的200 万条视频数据集被公布出来,这样的大数据正合深度学习胃口。这组数据集拯救了他的研究。
那是2017年春天,王赟去参加会议时得知这个消息,“当时就觉得这个东西可能真的就说拯救了这个领域。”果不其然,后续的许多相关研究或是全部或是部分使用了这组数据集。王赟则全部使用了,光是下载数据就花了整整一个月。这组数据还有一个特点就是弱标注——它没有标注事件的起止时间,而只标注了每段音频中的事件种类。这几乎和王赟的博士论文不谋而合。他的目标也就非常明确——如何在已有的检测基础上进行方法创新。他的这项技术可以做到在数以亿计的海量音视频信息中通过深度学习来直接锁定某些音视频片段。
从2007年10月开题以来,王赟在跟时间赛跑。“那会就想尽可能把东西往前赶,因为到2017年已是留学第七年了,已经开始超出(博士毕业时间)平均值了。”8年的博士生涯,王赟走了不少弯路,但他没有沉浸在失落的情绪中。“正如吃完第三个包子饱了不代表前两个包子就白吃了一样,我并不觉得我前四年是荒废了的。整整八年的学习,让我对语音识别、深度学习等各个领域的理论基础有了扎实的掌握。”也正因为有了前期曲折道路的铺垫,他在2014年搭上了深度学习的快车,也赶上2017年弱标注事件大数据公布的风口,而这些都需要时间的沉淀,“哪怕我前几年没走这些弯路,我如果(毕业)太早赶不上这两波,也做不出现在这个成果了。”
8年留学,王赟身边的朋友换了一波又一波,特别是硕士朋友,有人戏称他是“铁打的Maigo”,Maigo是王赟的英文名。不过他并没有散发出一种苦的气息,而是整天乐呵呵的。
事实上,他的留学生活并不是外界感觉的那般苦闷,他走进社团、周游城市周边、全世界旅游,把生活过得多姿多彩。他参加中国学生学者联谊会,在其举办的才艺比赛中,抱着吉它弹唱一曲《老男孩》,一炮而红。他参加pLayboycLub,与社团成员一起打狼人杀、一起做饭、滑冰、逛博物馆,一起去看樱花。他还在日语角、西语角和法语角跟外国人谈笑风生。
“我没有把留学的目的仅仅是学习知识,我确实不像有些同学那样有比如说有经济压力之类,我就觉得既然出来了就体验一下国外的生活,在读书的同时,尽可能丰富体验。”